在全球著名咨询机构Gartner发布的2022年顶级战略技术趋势中,Date Fabric不仅首先被提及,甚至被定义为“数据管理的未来”。作为新兴的热门市场,Data Fabric自诞生之日起就备受关注,全球最大的信息技术和业务解决方案公司IBM、数据集成领域领导者Talend、集成分析领域领导者TIBCO、元数据管理领导者Alation等全球各数据领域头部厂商都给出了对应的能力要求和解决方案。
从三年前的概念出现到如今落地实施并取得具体业务结果,Data Fabric海外爆火的背后反映了市场需求的变化。伴随数字化和智能化的推进,越来越多企业面临着高成本&低价值的数据集成、不断攀升的运维成本、不断增长的实时数据需求等多重挑战,基于主动元数据、语义、知识图谱、数据虚拟化、AI等技术的Data Fabric成为应对数据类型多样化以及数据量激增的最佳解决方案。
通过实施Data Fabric,企业不仅可以减少一半以上人力驱动的数据管理任务、70%的数据管理工作,让数据质量及运营成本降低65%;还能以8倍的速度、不到一半的成本,获取数据和洞察——基于Data Fabric产生的数据洞察,可以使企业平均每年增长30%以上。(数据来源:Gartner)
尽管以上每一项收益都足以让企业管理者心动,国内却迟迟没有基于这项全新的关键技术趋势完成系统化落地。曾任蚂蚁集团研究员(P10)、数据平台部总经理周卫林带领业界顶级数据专家团队创立Aloudata大应科技,致力于打造首个NoETL湖仓平台,内置增强数据目录、语义知识图谱、主动元数据、数据推荐引擎、数据虚拟化、数据编排和Dataops等Gartner定义的6大Data Fabric核心能力,是当前国内Data Fabric最佳实践。
国内Data Fabric最佳实践:NoETL重塑数据供给和管理方式
Data Fabric的终极目标是为数据集成和访问提供一种更灵活、更无缝、更自动化的方法。而Aloudata提出的NoETL方案,正是创始团队基于过去在蚂蚁集团建设金融级数据平台以及EB级数据管理经验所提炼的Data Fabric最佳实践,颠覆了传统模式下基于ETL的数据生产链路,致力于让企业每个人都能快速发现可信数据、自助分析全域数据,并实现主动、持续的数据治理,让企业数据随时就绪。
传统链路下,业务方和分析师提出任何一个数据需求,都绕不开ETL工程师这个中间角色,从找数、运维再到性能优化,各个环节都需要深度依赖ETL工程师才能完成,导致数据生产根本“快”不起来。
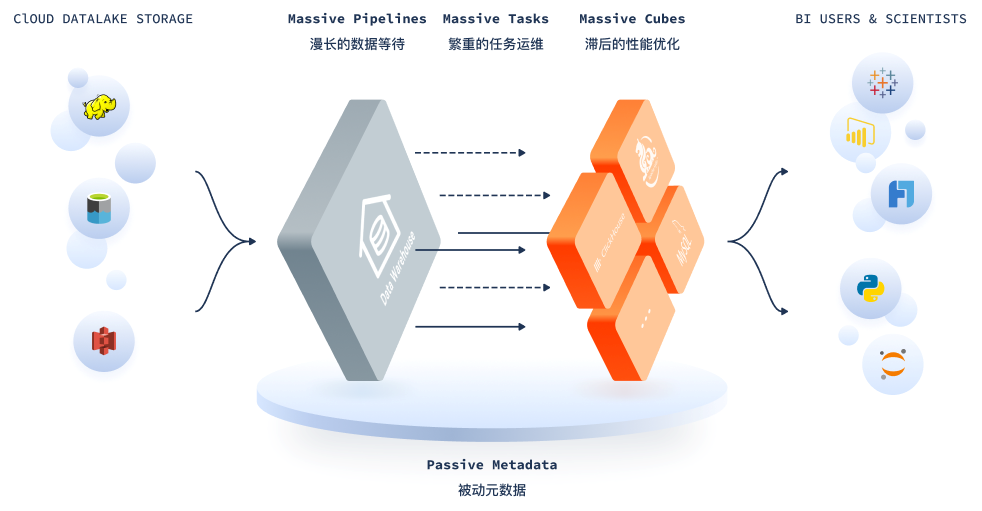
假设有100个数据需求被同时提出,ETL工程师就不得不安排优先级并逐一解决。然而爆发式增长的数据需求远远超出了ETL工程师的增长速度,在实际工作场景中,多达80%的数据需求无法满足,即便是有幸被满足的那20%,从提出需求到需求交付的时间至少以周计。
Gartner公布的数据再次印证了这一点:分析师80%的时间用于发现和准备数据,知识型员工将50%的时间浪费在寻找数据、发现和纠正错误以及确认不信任的数据来源上,数据科学家花60%的时间清理和组织数据。
不仅如此,不断增长、日趋复杂的ETL数据管道带来了治理困难和风险隐患,大量已失效的ETL任务无法得到及时下线,带来了严重的资源浪费,依赖于ETL工程师的机械式流程亟待改变。
NoETL问世,引领行业变革
所谓NoETL,是指在数据处理和分析环节,用户无需搭建复杂ETL链路、无需等待漫长排期即可灵活分析所有数据,实现敏捷数据洞察和高效一致的数据协作,能够以更低的成本、更迅速地做出可信业务决策。
NoETL的问世,无疑将引领一场前所未有的行业变革。提出这一理念的同时,Aloudata还进一步定义了具体可落地的NoETL技术标准——全场景自适应的弹性SQL引擎Aloudata AIR Engine(以下简称“AIR”),以帮助企业快速启用分析和洞察力,实现业务成功。

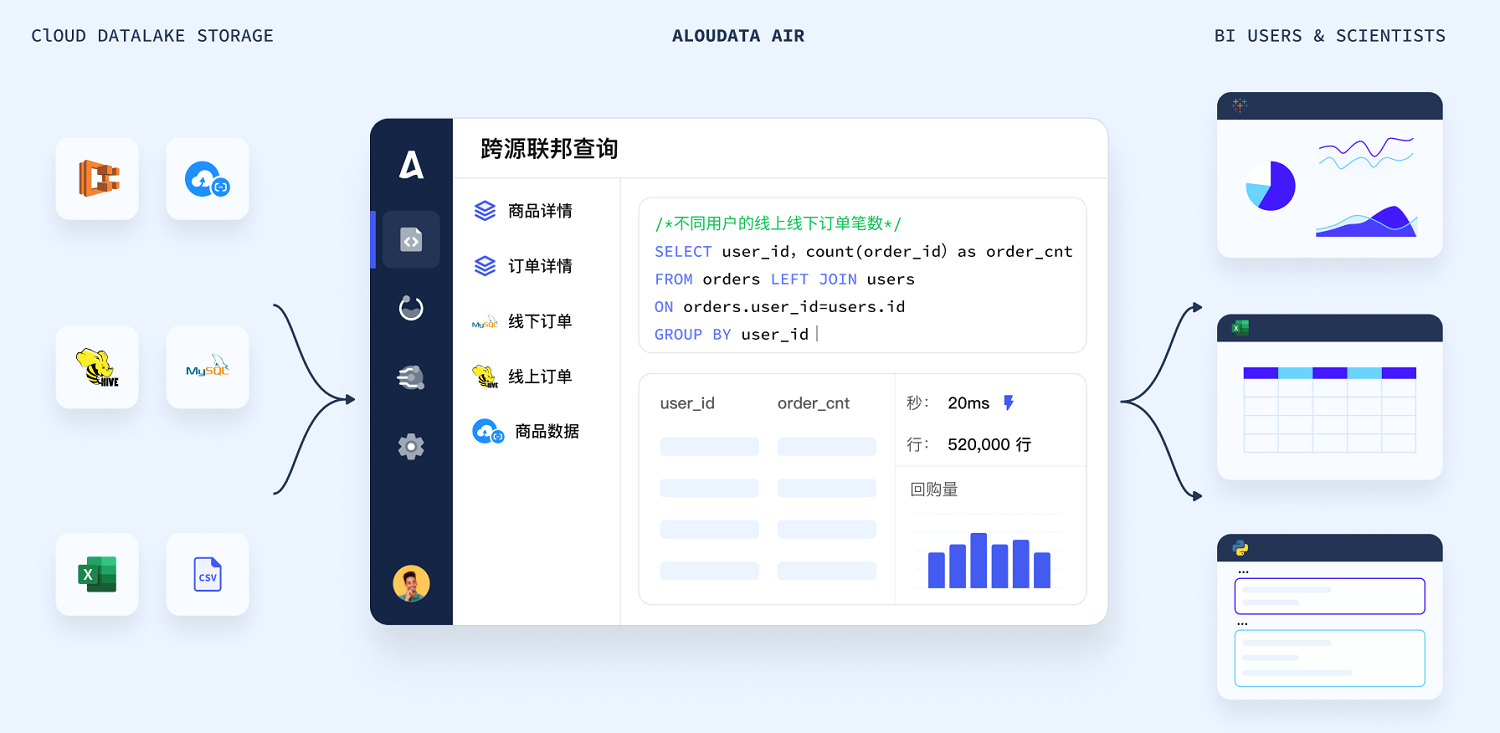
AIR基于NoETL理念做到无论数据是在数据湖、数据仓库或者其他地方,每个人都可在Ad-hoc、多维分析、报表等多场景下自助进行全域数据探索并定义一致的数据视图,帮助企业实现100倍性能提升、10倍以上数据化运营效率提升以及30%以上存储成本节约。
No Pipeline:去管道,无需关心数据位置
AIR通过湖仓查询引擎和数据虚拟化技术,实现多源异构数据查询和透明数据集成,大幅削减了数据搬运、控制了数据管道的无序增长。BI分析师减少了对ETL工程师的单向依赖,不需要再关心数据实际存放位置,也不必再搭建复杂的ETL数据管道,直接通过SQL定义弹性数据集就能够自助对全域数据进行数据准备和分析。
No Task:免运维,无需操心任务运维
无需人工任务运维,AIR能够通过对用数行为的收集和观察,实现数据生产链路的智能编排、运维和治理,针对重复、相似计算进行自动合并,针对无效、低频、低价值数据的生产任务进行降权或下线,以“销”定产,大幅节省管理投入。
No Cube:自优化,无需担心查询性能
AIR 基于用户查询行为实现了自适应的查询性能优化,无需Cube/索引构建,BI分析师可自助完成数据准备,无需担心查询性能,专注业务分析与洞察。
通过对现有数据生产链路的优化与升级,AIR让企业每个人随时可对全域数据开启自助分析与洞察,快速突破ETL工程师人力瓶颈,充分释放过去因为ETL资源受限而被堆积和抑制的运营分析需求。
NoETL落地某大型股份制银行:10倍提升数据化运营效率
随着业务数字化运营不断深入,某大型股份制银行于数年前开始引进和自研BI工具,并大规模推行全行分析师自助分析和报表制作,截止2021年,全行报表达数千张,月活看数人群达万级,并仍在高速增长中。
数据分析和报表制作环节的自助,进一步催生了行内数据分析需求的爆发,但前置的数据准备环节却无法同步提高产能,数据运营效率仍然存在显著瓶颈。究其根本,在于该银行现有的基于ETL的数据生产链路存在以下弊病:
-数据分散在数据仓库、数据湖和业务数据库中,分析师开展数据分析和报表制作往往需要依赖ETL团队对数据进行汇集和预加工,交付周期以周计;
-当前基于ETL的数据集成和加速方案需要对数据做大量搬运,显著拖慢了报表的数据时效;
-业务数据分析需求快速变化,ETL工程师预先设计的数据查询加速方案很难同时兼顾灵活性和性能,报表查询性能难以保障。
可见,当前基于ETL的数据供给模式已经无法支撑快速增长的数据分析需求。
为解决上述问题,该银行基于Aloudata AIR Engine自研了敏捷数据准备平台,为全行分析师提供了全域自助找数、面向业务语义准备数据、查询自适应加速的敏捷数据分析体验,让全行分析师可以端到端全自助完成数据分析需求交付,将业务取数看数效率从周级缩短到了天级,并实现了高性能、低时延的报表看数体验,10倍提升全行数据化运营效率。
NoETL,驱动企业增长的数据引擎
Data Fabric在国外大受追捧,而在国内刚刚起步。正如10年前大数据概念在国外兴起,不到3年就被中国广泛应用,可以预见的是,Data Fabric在国内也将被越来越多的企业用于解决数据资产多样性、分散性、规模化和复杂性不断增加以及数据使用人群和应用场景爆发式增长带来的一系列问题。
作为国内Data Fabric先行者,Aloudata致力于帮助企业快速构建面向未来的下一代数据平台,摆脱传统低效的数据供给与管理方式,轻松应对未来日益复杂的数据环境和蓬勃旺盛的业务分析需求,帮助业务寻找新的机会点和创新点,建立可持续发展机制与核心竞争力。目前,Aloudata已与多家顶级金融机构合作共创,基于真实复杂的业务场景,探索全民可用的NoETL新模式。
【关于Aloudata】
Aloudata(浙江大应科技)是一家NoETL湖仓平台服务商,Data Fabric理念践行者。公司创始人曾任蚂蚁数据平台部总经理(P10),是蚂蚁数据技术主要开拓者和奠基人;创始团队均为原蚂蚁集团数据平台核心成员。Aloudata是数据湖仓架构的先行者,自主研发的AI增强湖仓引擎可实现数据分析性能自适应优化以及数据治理“自动驾驶”,帮助企业实现10倍以上的数据化运营效率提升。目前,Aloudata已顺利完成两轮融资。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。