OpenAI的新模型o1,可谓是开启了Scaling Law的新篇章——
随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算),o1在逻辑推理能力上已经达到了目前天花板级别。
尤其是在北大给出的一项评测中,o1-mini模型的跑分比o1-preview还要高:
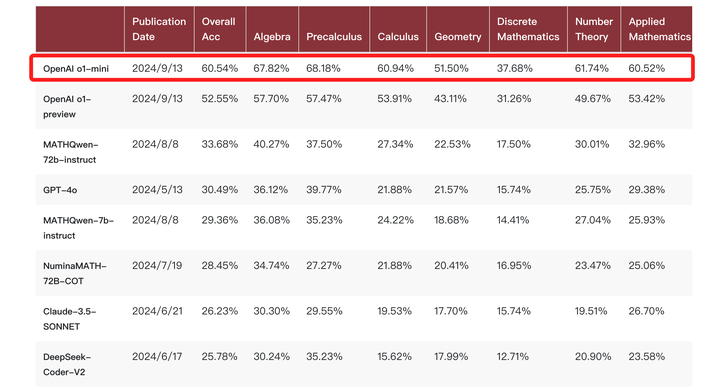
这就展示一种新的思路和可能性——
小模型专门加强推理能力,放弃在参数中存储大量世界知识。
OpenAI科学家赵盛佳给出的解释是:
>o1-mini是高度专业化的模型,只关注少部分能力可以更深入。
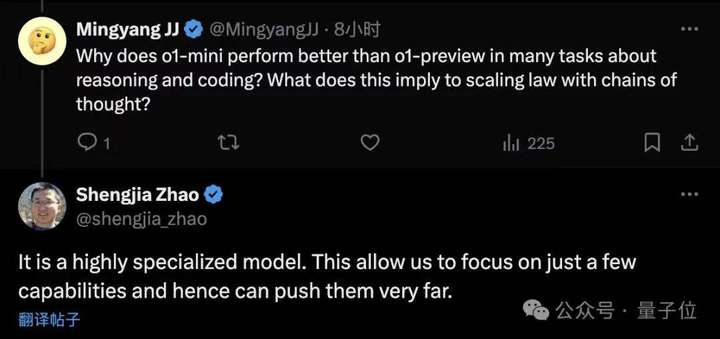
但与此同时,也出现了另一个问题:
若是想让AI同时掌握高阶推理能力和大量知识的任务应该怎么办?
于是乎,技术的聚光灯再次对焦到了大模型和RAG的组合。
具体而言,向量数据库让大模型能够快速有效地检索和处理大量的向量数据,为大模型提供了更丰富和准确的信息,从而增强了模型的整体性能和应用范围。
可以说是让大模型有了“好记忆”,减少出现答非所问的情况。
而且这一次,小模型专业化的新趋势还对RAG中的向量数据库提出了更高的要求:
一方面是小模型存储的知识少了,对于外部知识存储和检索的质量要求就更高。
另一方面是AI应用落地的脚步加快,面对多用户、高并发的场景,对整个系统的性能也更高。
在此背景下,业界先进企业正将目光投向更强大的分布式向量数据库。
向量数据库代表玩家星环科技就和英特尔强强联手,对此提出了一种新解法:
用更强性能的数据中心CPU与酷睿™ Ultra支持的AI PC组合,加上专门优化过的分布式向量数据库,提供更经济、更通用的方案,有效解决企业部署大模型的瓶颈问题。
分布式向量数据库推动大模型应用落地
正如我们刚才提到的,RAG的重要组成部分就是外挂的专业知识库,因此这个知识库中需得涵盖能够精准回答问题所需要的专业知识和规则。
而要构建这个外挂知识库,常见的方法包括向量数据库、知识图谱,甚至也可以直接把ElasticSearch数据接入。
但由于向量数据库具备对高维向量的检索能力,能够跟大模型很好地匹配,效果也较好,所以成为了目前主流的形式。
向量数据库可以对向量化后的数据进行高效的存储、处理与管理。
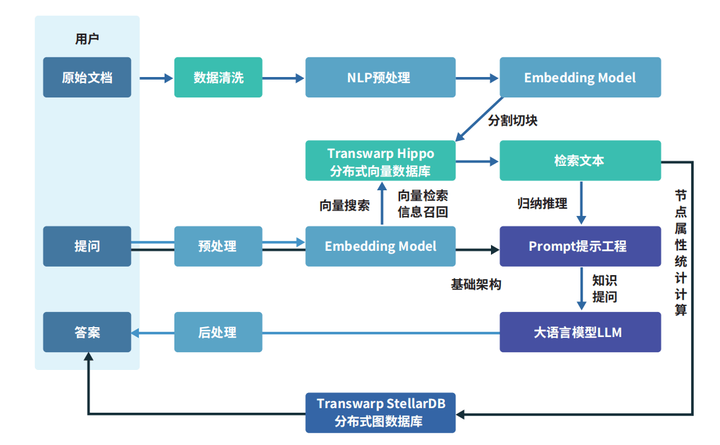
如下图展示的那样,数据向量化过程利用了诸如词向量模型和卷积神经网络等人工智能技术。
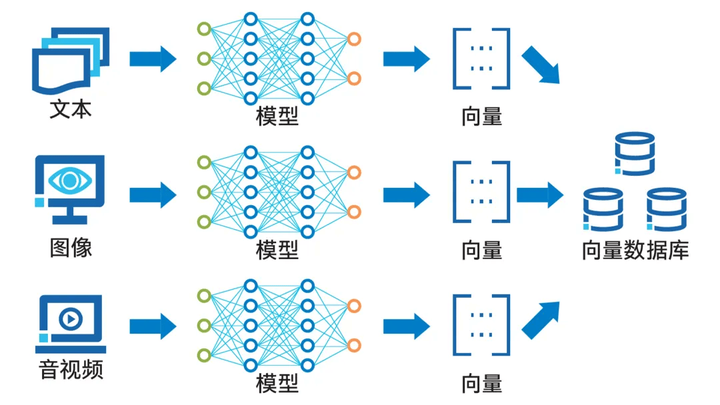
通过Embedding过程,这些技术能够将文本、图像、音视频等多种形式的数据转换成向量形式,并将其存储在向量数据库中。
至于向量数据库的查询功能,则是通过计算向量间的相似度来实现的。
星环科技所提出的创新成果,便是无涯·问知Infinity Intelligence。
这是一款基于星环大模型底座,结合个人知识库、企业知识库、法律法规、财经等多种知识源的企业级垂直领域问答产品,可以实现企业级智能问答。
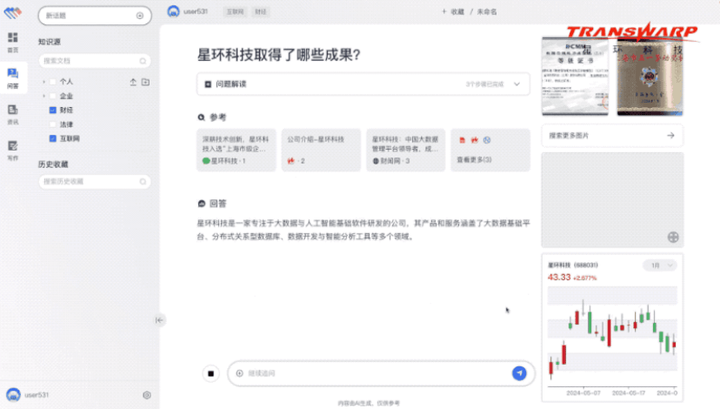
例如面对“国家大基金三期会投向哪些领域”这样非常专业的问题,无涯·问知不仅可以轻松作答,还能提供相关图谱、关键信息等:
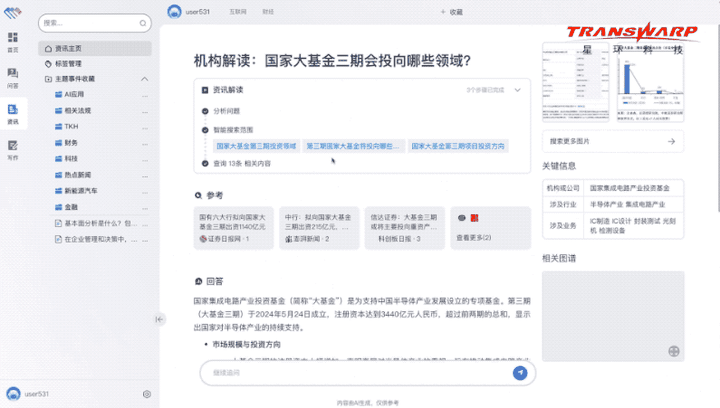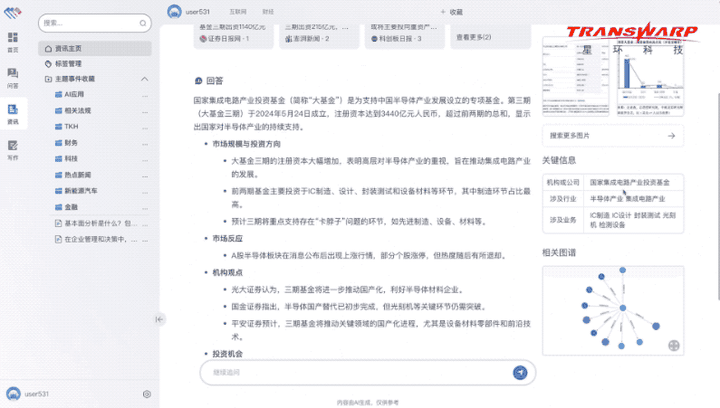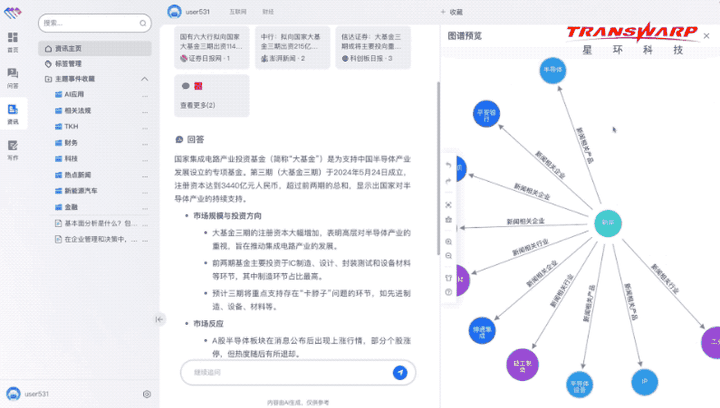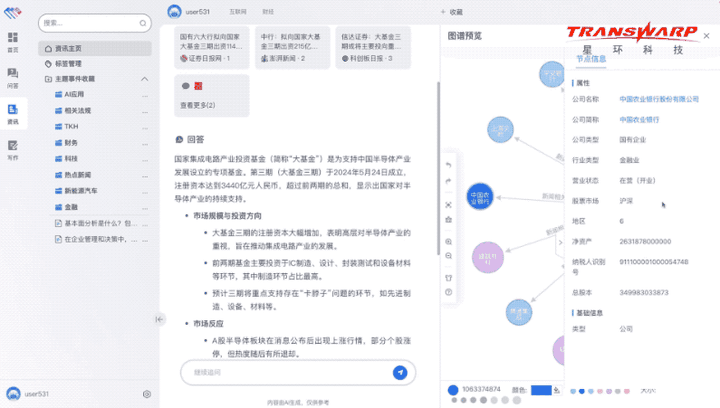
而且还能图文并茂地展示作答:
上传本地的视频文件等,无涯·问知“唰唰唰”地就可以做总结:
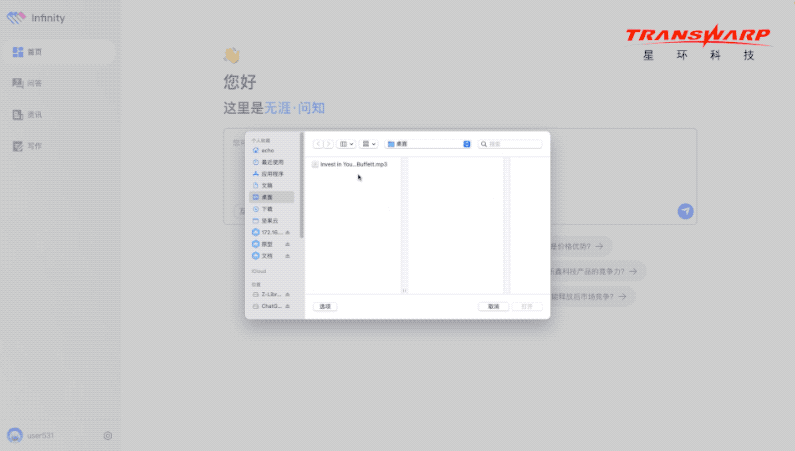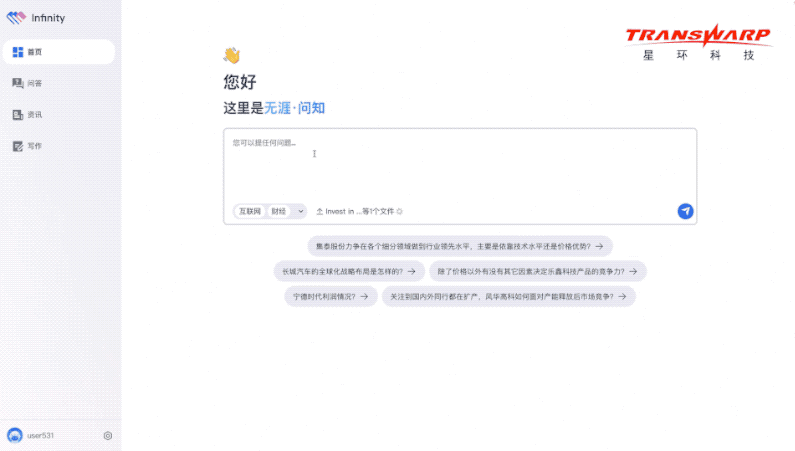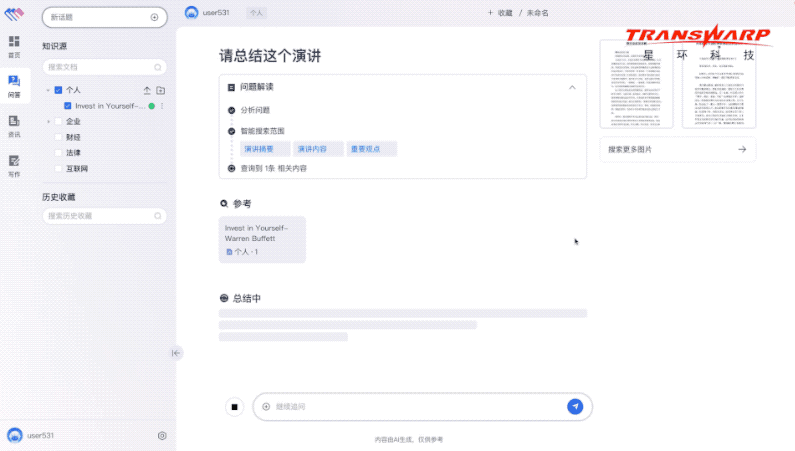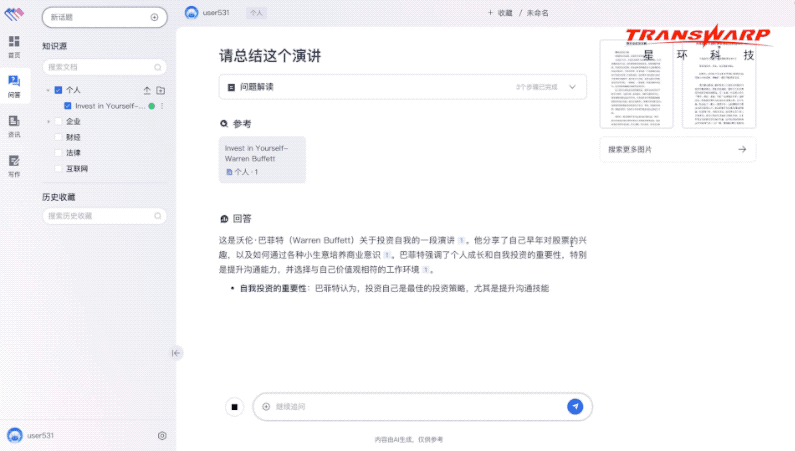
整体来看,无涯·问知在个人知识库上,支持用户一键上传文档、表格、图片、音视频等多模态数据,快速实现海量多模知识的检索与智能问答。
在企业知识库方面,则是通过管理端构建企业知识库后,员工可以基于企业知识库进行问答,知识库作为企业内部的知识共享平台,促进不同团队和部门之间的协作和信息交流。
除此之外,无涯·问知内置了各大交易所的交易规则、监管要求等常见的法律法规知识,用户可针对法律法规的具体条款、监管规则、试行办法等提出问题,无涯·问知将提供法律风险预警以及应对建议。
它还内置了丰富的上市公司财报和产业链图谱数据,能够为金融机构提供全面深入的投资研究分析工具。
即便是面对金融、法律等众多既要求时效性、又要求数据隐私的行业,星环也有无需上云联网的无涯问知AI PC版,它可以在配备英特尔® 酷睿™ Ultra的主流个人电脑上,基于集成显卡和NPU流畅运行。
它不仅具备强大的本地化向量库,支持多格式、不限长度的文件资料入库,还支持影、音、图、文等多模态数据的“知识化”处理,以及“语义化”查询和应用能力,极大地丰富了知识获取和应用场景。
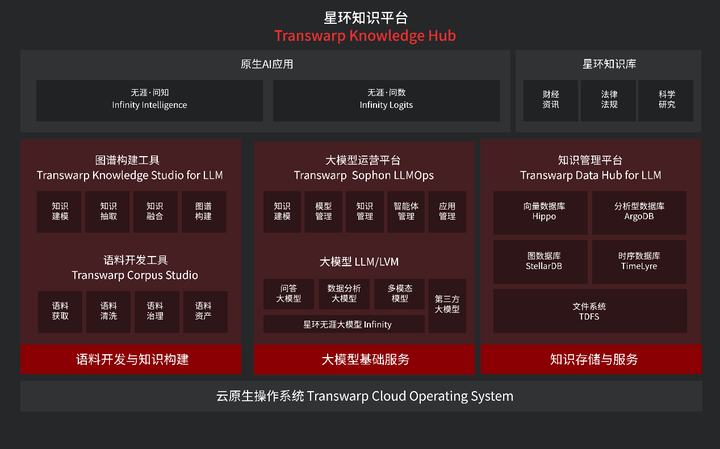
无涯·问知可以算是星环知识平台Transwarp Knowledge Hub中重要的组成部分,其为用户打通了从人工智能基础设施建设到大数据、人工智能等研发应用的完整链条。
值得一提的是,TKH同样提供了AI PC版本,基于本地大模型技术,能够回答用户各类问题,为用户带来文档总结、知识问答等全新体验,同时保障用户隐私数据安全。
AI PC版本星环大模型知识库提供本地大模型和远程大模型供选择,简单问题可以由本地模型快速处理,而复杂疑难问题则可以提交给云端大模型进行深入分析。
这种弹性扩展的能力,确保了企业在面对不同挑战时,都能够获得足够的计算支持。
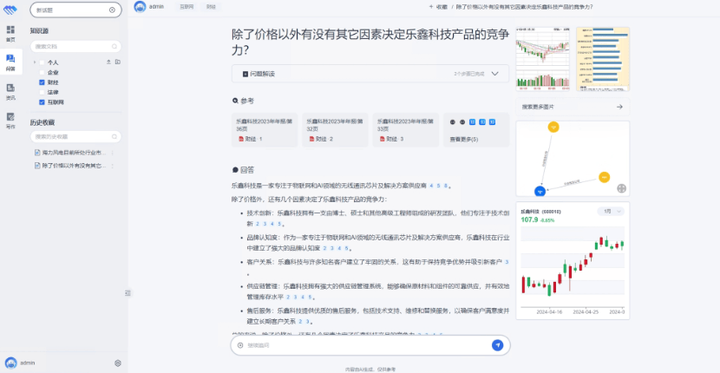
而这一系列产品之所以能够做到在云端和本地都能提供高效的知识管理和智能化工具,离不开星环科技自研的几个关键技术。
首先就是基于星环自研向量数据库Hippo的向量索引技术,能够在庞大的数据集中快速精准地召回相关信息,提升了信息检索的速度和准确性,使模型在处理查询时更加高效。
其次是利用了图计算框架,让大模型能够识别实体间的多层次关系,从而进行深度的关联分析,提供了更为深入和准确的洞察结论。
在数据方面,覆盖官方资讯、门户类网站、自媒体财经等1600多个信息源,涵盖了全市场的各类宏观、价格指数以及大部分新闻数据。
不仅包括通常渠道可获取的数据,还包含高可信度、拥有第一手资料的新闻合作商数据,同时也对所有官方政策数据进行实时全覆盖。
但随着大模型的发展,数据规模可谓是极速暴增,这就对数据库和智能问答的性能提出更高要求。
因此,数据压缩、算力提升也成为了各个大模型玩家发力的关键点。
在这方面,星环科技与英特尔深度合作,从端侧的AIPC到后端的数据中心和云,通过软硬协同优化为大模型的应用落地打造了可行的方案。
CPU助力向量数据库应用性能大幅提升
向量数据库搭配CPU,其实本来就已经是行业内现阶段的主流共识。
究其原因,向量相似度检索、高密度向量聚类等都属于CPU密集型负载。因此,CPU的性能至关重要。
第五代英特尔® 至强® 可扩展处理器,正是带来了一系列面向AI时代的关键特性更新。
首先,它搭载了更大容量的高带宽内存,有效缓解了向量数据库中数据密集型工作负载的内存墙问题。
此外,它还集成了英特尔® AMX(高级矩阵扩展)加速引擎,能高效地处理向量数据库查询所需的矩阵乘法运算,并在单次运算中处理更大矩阵。
对于云端部署的版本来说,搭载第五代至强® 处理器后,星环Transwarp Hippo的整体性能较第三代提升高达2.07倍。
那么本地AI算力,是否能支撑在AI PC上使用大模型来支持企业应用呢?
星环尝试后给出了答案:完全够用。
从AI PC诞生到现在近一年时间,整体AI算力提升了200%多,能耗又降低了50%。
这背后就要归功于英特尔® 酷睿™ Ultra系列CPU的升级改进了。
在最新的英特尔® 酷睿™ Ultra 处理器 (第二代)200V系列处理器支持下,整个AI PC平台算力最高能达到120 TOPS。
特别是其中搭载的第四代NPU,性能比上一代强大4倍,非常适合在节能的同时运行持续的AI工作负载。

在软件层面,英特尔和星环合作,还对数据库底层做了性能优化。
通过水平扩展架构、基于CPU的向量化指令优化、多元芯片加速等技术,有助于分布式向量数据库发挥并行检索能力,为海量、多维向量处理提供强大算力支持。
经过优化后的Transwarp Hippo实现了海量、高维度向量数据处理,并具备低时延、高精确度等优势。
同时提升了Transwarp Hippo了服务器节点的性能密度,在性能提升的同时,具备更高的每瓦性能,有助于节省单位性能的能耗支出,最终体现为降低总体拥有成本 (TCO)。
存算融合趋势明显,CPU大有可为
随着OpenAI o1系列为代表的大模型不断革新算法,大模型推理时的算力消耗正在飞速攀升,对支撑大模型运转的基础设施平台提出了更高的要求。
特别是对于需要频繁访问外部知识库的大模型应用,存储与计算深度融合俨然成为当务之急。
在这一技术变革大潮中,CPU成为其中关键角色之一。
此外,英特尔基于CPU的解决方案还为用户带来了更具成本优势的选择。由于通用CPU拥有成熟、完善的供应链体系和生态支持,企业用户可以获得稳定可靠的算力供给。
同时,英特尔® 至强® 和酷睿™ 处理器能同时覆盖端侧和云侧的算力需求,为不同的应用场景提供强大的支持。
展望未来,存算一体化的趋势将愈发明显。
从大模型应用的角度看,知识检索和AI推理将不再泾渭分明,而是深度交织、彼此强化。
在这样一个智能融合的未来图景中,CPU作为连接存储、网络和各类加速器的纽带,其地位将变得举足轻重。(文章来源:量子位,作者:梦晨 金磊”)
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。